作家:周雅开云体育
作家|周雅
在AI圈子里,大众梗概听到过这么的话术,“AI翻新既是一场马拉松,亦然一场短跑”,此时此刻我在AMD Advancing AI这场关乎将来AI缱绻模式的会上,脑中屡次浮现出这句话。
太平洋时间2025年6月12日清晨,圣何塞的麦克内里会议中心就开动排长龙,外传本年注册的不雅众严重超标。身前死后的全球媒体同业,着实齐在辩论近期某个模子或某个AI公司的进展,AI的热度像是6月份的天气。我于是又刷了一下AMD的最新财报,在2025年第一季度,AMD的数据中心业务营收37亿好意思元,同比增长57%。对应到全球AI邦畿,AMD的话语权渐渐变重。
镜头拉回到随后的会议现场,AMD董事会主席及首席实施官Lisa Su博士走上舞台,也就意味着这场本事大会的认真开动了。
概述这场发布,AMD主要作念了五件事:展示AI加快器“Instinct MI350系列”的遥遥起始;用开源软件平台“ROCm 7”普惠AI开发者;发布支握以太网定约(UEC)的网卡Polara 400;以及带来一个彩蛋行动压轴——AI机架“Helios”。
听圆善场,不丢脸出AMD的政策标的,从“卖芯片”转向“不啻卖芯片,还卖系统”,左手端到端贬责决策,右手怒放生态,来重塑AI基础步调的竞争模式。
Helios:咱们不啻卖芯片,还卖端到端贬责决策
尽管NVIDIA在GPU的强势有目共睹,但AMD也并不想作念一个永久追逐者。
咱们知谈,NVIDIA 一直是靠着硬件GPU+软件生态CUDA +网罗本事NVLink,建了一个严丝合缝的AI生态。而AMD 匠心独具,用组合拳CPU+GPU+DPU+开源软件栈,武装成一个端到端的AI 基础步调。
于是,AMD认真官宣AI机架决策「Helios」,将于2026年认真问世。
「Helios」 是一个集大成者,AMD会把全家桶齐打包装进去,包括下一代 AMD GPU Instinct MI400 系列 、取舍 Zen 6 架构的AMD CPU EPYC 「Venice」、AMD DPU Pensando 「Vulcano」、以及AMD开源软件栈ROCm。
此处稍作解释AI机架决策。在以前,像谷歌、Meta 这么的大公司要我方成为“攒机员”,他们从 AMD 或其他芯片厂商那处买来GPU/CPU 等中枢部件,然后我方遐想处事器、机柜、散热系统和网罗一语气,再进行漫长的软件调试,才气让数见不鲜个 GPU 协同使命,不言而喻,这个经过耗时耗力耗钱。
你不错把「Helios」 贯通成一台为你拼装好、调试好、开箱即用的“超等缱绻引擎”,它的外不雅形态是一个机架,里面有最矫捷的GPU,还预装了最匹配的 CPU、最高效的网卡、专门遐想的散热和供电系统,且通盘软件齐经过深度优化,而不是让你我方去买一堆零件(CPU、显卡、主板、网卡等)追忆我方攒机,说白了,即是为了贬责超大范围客户在构建 AI 集群时濒临的最大痛点——斥责总领有本钱(Total Cost of Ownership,TCO)和缩小居品上市时间(Time-to-Market,TTM)。
“Helios是业界初度将机架行动转圜系统遐想,它将在大范围肃肃和散布式推理鸿沟占据起始地位,这将透彻改变行业模式。”Lisa Su博士说谈,“Helios的上风不啻于矫捷算力,在内存容量、内存带宽和互联速率方面齐遥遥起始。”
AMD直面竞争也颇有底气。官方称,Helios可容纳72块MI400系列,总带宽260TB/s,FP4 2.9 EFlops、FP8 1.4 EFlops。此外,Helios的HBM4内存容量31 TB、总带宽1.4 PB/s、横向推广带宽43 TB/s,对标NVIDIA Oberon齐要跳跃一半。
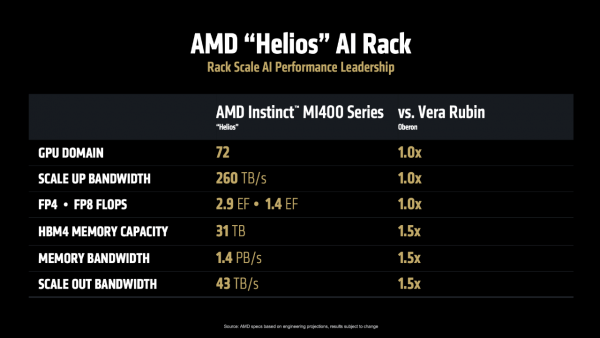
而驱动 Helios 的中枢,恰是 Instinct MI400,这款加快器正在开发中,其规格号称恐怖,当屏幕上出现它的性能参数时,现场掌声雷动:
FP4 算力达到 40 PF,FP8 算力达到 20 PF,单 GPU 显存高达 432GB,HBM 内存带宽达到19.6 TB/s,单 GPU 对外互联带宽达到300 GB/s,可终了跨机架和集群的互联。陋劣来说,它能够让不同机柜和缱绻群组之间进行超高速数据交换,就像给通盘缱绻单位之间铺设了信息高速公路,使得数据能够快速、无数地在不同斥地间流畅,幸免堵塞或延长。

看下图这条陡峻的弧线。从 MI300 到 MI350,性能擢升了约 3-4 倍;而从 MI350 到 MI400,AMD但愿让它跑出一骑绝尘的姿态。Lisa Su博士在展示性能弧线时说谈:“MI400系列在处理最前沿的模子时,性能展望可擢升至目前的10倍,这使它成为业界性能最强项的AI加快器。”
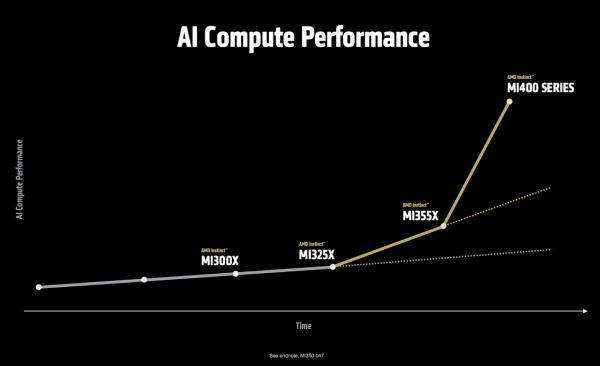
从道路图上看,Helios将于2026年发布,而 AMD 依然放出了“三年谋略”:2026年,Helios将基于AMD EPYC “Venice”、AMD Instinct “MI400系列”、AMD Pensando “Vulcano”;2027年,“下一代AI机架”将基于EPYC “Verano”、Instinct “MI500系列”、Pensando “Vulcano”。
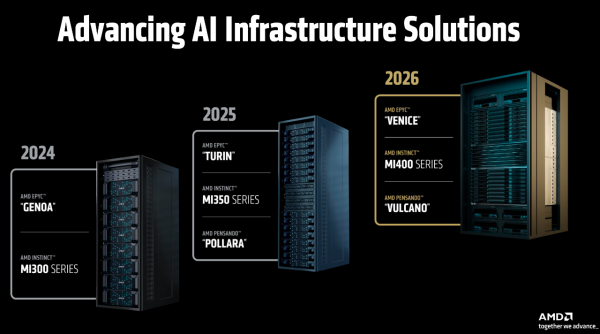
诚然,这是 AMD 政策上的一次紧要升级,意味着这家公司正从一个纯正的芯片供应商,向系统级贬责决策提供商转型。
说到这里,AMD故意请来OpenAI助阵,两家公司齐强调了AI缱绻才略有多珍重。OpenAI酌量创始东谈主兼首席实施官Sam Altman坦言:“当咱们开动使用推理模子,这些模子需要很长的运算时间。这种模子会自主运行,对问题进行分析,然后给出更优解,无意以致能径直写出一整套圆善的代码。但这就条款模子必须运行得更快,还得能处理很长的笔墨。为了作念到这些,咱们需要超等多的缱绻资源、存储空间和CPU。”

也即是说,推理模子和AI代理正在驱动下一波哄骗波澜,这对算力的需求是无很是的。
Instinct MI350:绝非单一目的,性能、内存、本钱全要眷注到
除了让东谈主咫尺一亮的Helios,Lisa Su还揭开了本场第一位硬件主角——AMD Instinct MI350 系列!

AMD董事会主席及首席实施官Lisa Su博士手握MI350系列
具体来看,MI350系列取舍CDNA 4 GPU架构,3纳米,它的特色是:1、更快的AI肃肃和推理:AI算力较上代擢升4倍,在FP4精度下可达20PF,同期在FP6精度下可擢升肃肃和推理的速率;2、支握更大的大模子:由于每个模块齐配备了288GB HBM3E高性能内存,是以单个GPU就能运行5200亿参数的模子,不言而喻,这就成心于斥责大模子推理的本钱;3、支握快速部署AI基础步调:该系列基于行业圭臬的UBB8平台,支握“风冷”和“液冷”两种散热决策。


天然,为了适合各类化的数据中心环境,MI350 系列推出了两款型号:MI355X 和 MI350X。两者分享一样的缱绻架构和内存规格,但在功耗和散热决策上却不一样:MI355X 追求极致性能,功耗较高,主要面向最高效的液冷散热环境;而 MI350X 则更良好能效,功耗较低,支握风冷和液冷两种散热款式,这种天真性让它能够“在现存基础步调上快速部署和哄骗”。


提到数据中心的散热款式,此处有必要插入AMD副总裁兼数据中心加快业务总司理 Andrew Dieckmann的不雅点。他在前一天的媒体调换会上指出:“2025年是液冷本事的珍重里程碑”——目前通盘在建的数据中心、以及前期谋略中的数据中心技俩,基本齐将取舍液冷决策,这是因为它能带来更低的TCO,永远来看更具经济效益,这是AMD前进的标的;同期,风冷市集需求依然强项,尤其是在企业里面部署场景中,AMD也会推出相应的居品线。
连接说回 MI350 系列的性能,俗语讲“是骡子是马拉出来溜溜”,「性能」一直齐是猜度 AI 加快器的标尺,AMD这次也摆出了MI350 系列与其他居品的径直对标,不仅对标自家居品,还对标友商NVIDIA的居品。
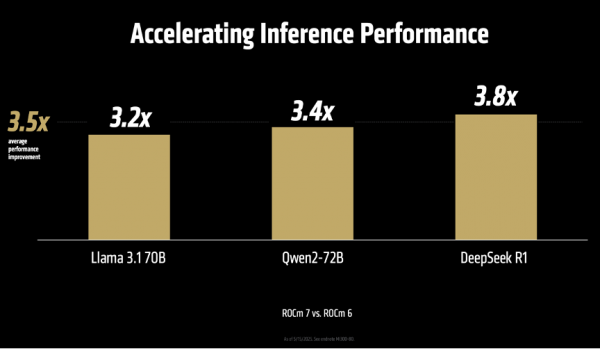
起始,在推感性能方面。MI355X 对比上一代 MI300X,在运行 Llama 3.1 405B(4050亿参数)这么的大模子时,推理迷糊量最高擢升可达 4.2 倍,在AI Agent、本色生成、文本选录、聊天对话等多种场景中,举座性能也擢升了3-4倍。而且,这一上风并不仅限于特定模子,在 DeepSeek R1、Llama 3.3 70B、Llama 4 Maverick等多个典型模子上,迷糊量均终闪现卓著 3 倍的性能擢升。
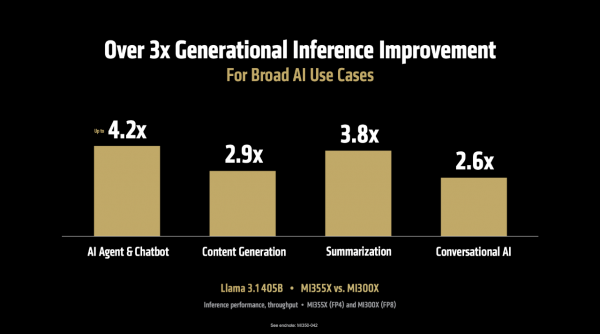
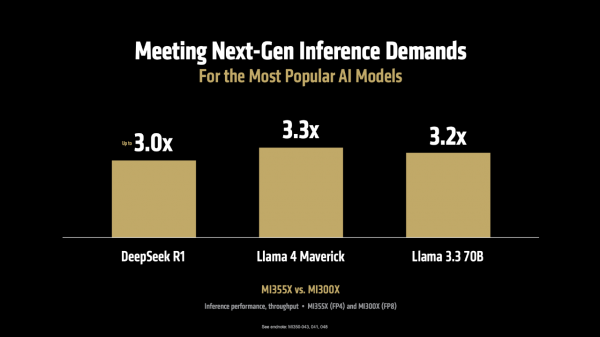
当运行 DeepSeek R1和 Llama 3.1 405B 模子时,在使用 SGLang、vLLM 等流行的开源推理框架时,MI355X的性能比使用独到框架(TensorRT-LLM)的NVIDIA B200 更胜一筹。如下图,MI355 比拟 B200 离别在SGLang、vLLM上每秒处理的 token 数目跳跃1.2倍、1.3 倍,在vLLM上每秒处理的 token 与 NVIDIA GB200握平。
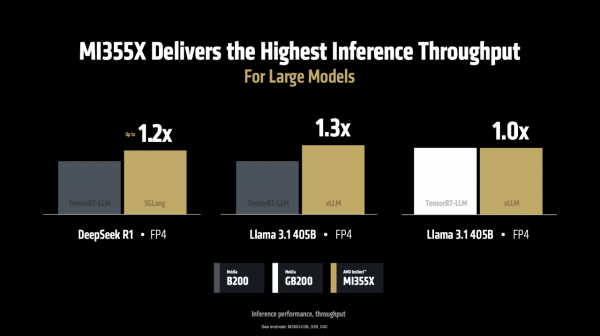
更珍重的是,这种性能上风径直更正为本钱上风:“每好意思元能处理40%的token”,这意味着客户不仅能赢得更快的推理速率,还能大幅斥责处事本钱,这关于以 token 计费的 AI 哄骗来说是致命的眩惑。

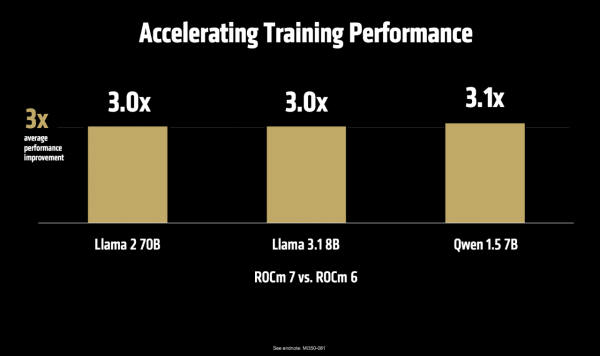
其次,在更要津的模子肃肃方面。MI355X 对比 MI300X,在Llama 3 70B预肃肃的迷糊量擢升 3.5 倍,在Llama 2 70B模子微调方面的性能擢升 2.9 倍,这就成心于缩小从开发到部署的周期。
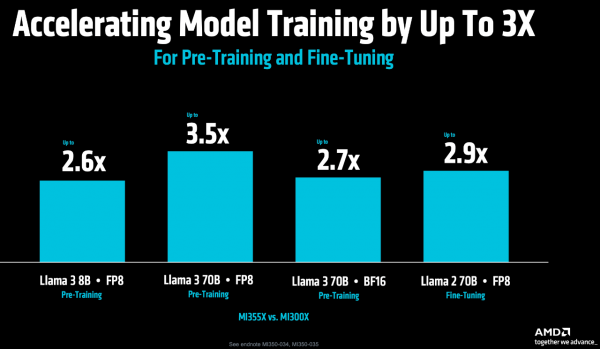
在Llama 3 70B/8B的预肃肃任务中,MI355X 对比 NVIDIA B200,两者性能旗饱读很是;而在最新的MLPerf V5.0基准测试中,MI355X 在Llama 2 70B模子微调方面的性能,对比B200和GB200离别快1.1倍、1.13倍。

基于MI350系列,各家OEM厂商推出了取舍AMD本事的AI机架决策,整合了EPYC CPU、Instinct GPU和Pensando DPU,全部整合为一体化贬责决策。在大范围部署环境中,单个液冷机架最多可容纳96个GPU,以致可推广至128个GPU,配备2.6 ExaFLOPS FP4算力和36TB HBM3e高速内存。而在风冷散热系统的部署决策中,MI350系列机架单柜可支握64个GPU,兼容传统数据中心的部署环境。
“这么的天真性和各类化取舍是客户真确需要的,他们但愿用最少的使命量和最小的打扰,终了数据中心快速部署,这恰是MI350能够终了的功能。”Lisa Su博士强调。


据悉,MI350系列已于本月初开动量产出货,首批相助伙伴也将如期发布处事器居品,并在第三季度推出公有云处事。AMD指出,下图的名单是MI350系列的相助伙伴,但这不是全部,还会陆续更新。

ROCm 7:只好硬件是不够的,软件生态是开发者构建AI的画笔
若是说硬件是 AI 缱绻的“肌肉”,那么软件生态即是它的“神经系统”。“硬件性能天然出色,但真确开释其全部后劲的要津在于软件。”Lisa Su博士将话题转向了AMD的软件生态——ROCm。
说到软件生态,AMD有ROCm,NVIDIA有CUDA,然而大众常常不会把两者口舌不分,为什么?
关于这个敏感问题,AMD东谈主工智能行状部企业副总裁 Ramine Roane是这么回应的:
“咱们开发了HIP讲话,它和CUDA有90%相似,不错说是一个亲手足。咱们以致提供了叫HIPify的调治器用,只需几行代码就能把CUDA程序转成HIP体式。
但其终了在更珍重的趋势是,开发者还是不需要径直战争底层编程了。你不错径直用PyTorch、Jax或者从Hugging Face下载模子,这些在咱们平台上的使用体验,跟在英伟达平台上统转圜样。
关于那些如实需要写底层代码的高档开发者,除了用HIP以外,目前业界有个更好的趋势——使用Triton这么的通用编译器。这是OpenAI开发的器用,微软、Meta齐在用,它收受Python作风的代码,然后自动为不同硬件平台生成最优代码。陋劣到什么进度?咱们比赛中有个16岁的高中生,仅靠编写陋劣的Python代码就干预了前20名。
行业正在从硬件专用讲话转向通用讲话,因为只须性能达标,大众齐更欢跃用一种代码运行在职何硬件上,而不是被特定平台绑定。”
弦外之音即是在说,CUDA的护城河其实莫得想象中那么深不可破,每当有新的GPU架构出刻下,无论是NVIDIA我方的如故竞争敌手的,通盘东谈主齐必须从头优化底层代码,很是于回到同沿途跑线。而开源生态的上风在于集世东谈主之力,速率更快,翻新更活跃,AMD恰是借助这少量来撼动NVIDIA的市集主导地位。
好,让咱们回到现场。
AMD东谈主工智能行状部高档副总裁Vamsi Boppana用一句话详细ROCm的愿景——打造怒放分享的、可推广的软件平台,让AI翻新惠及全球每一个东谈主。
目前,已有超180万个Hugging Face模子可在ROCm上开箱即用。以前一年来,AMD加强了对JAX的支握,借助MaxText等程序库,JAX在肃肃技俩中的哄骗日益无为。更珍重的是,AMD将软件更新频率从季度缩小至每两周一次,确保能够为最新的模子和框架提供“Day 0”支握。
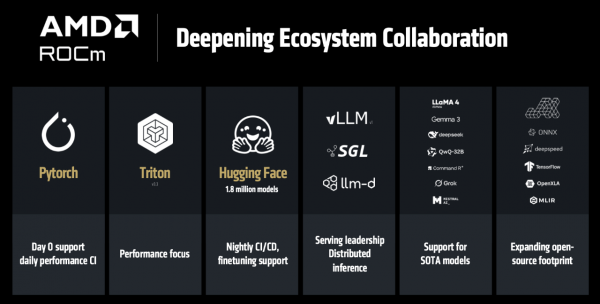
然而AI 一直在使命,是以AMD也弗成懈怠,于是认真发布——ROCm 7,重心优化了推感性能,宗旨是擢升易用性和性能。其预览版将于 6 月 12 日向公众怒放,郑再版将于 8 月发布。

“咱们全面更新了AI推理的本事架构。从VLLM和SGLang这些基础框架的升级,到擢升处事性能、支握更高档的数据类型,再到开发高性能的中枢程序,以及终了Flash Attention v3这么的前沿算法。咱们让路发经过变得更陋劣,用肖似Python的款式来整合各类中枢功能。咱们还大幅修订了系统里面的通讯款式,这让ROCm 7的推感性能比上一代ROCm 6擢升了3.5倍、肃肃性能擢升了3倍。”Vamsi Boppana指出。
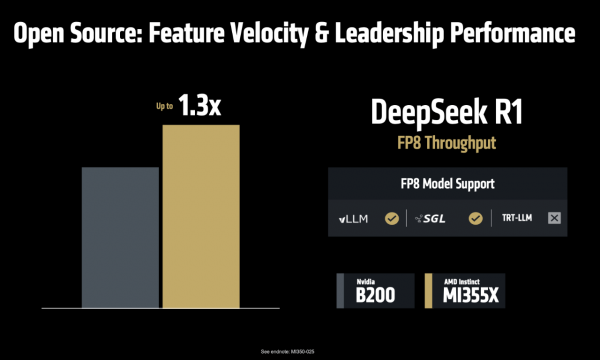
说到这里还不忘强调开源的平允,趁便硬刚一下友商。Vamsi Boppana说,“在AI推理处事的鸿沟,咱们越来越发现,开源的贬责决策在功能更新速率和性能进展上齐已卓著不公开源代码的决策。比如VLLM和SGLang这么的开源框架,它们的代码更新速率相配快,还是起始终闪现FP8这种优化功能,比那些闭源居品早好多。咱们与这些开源社区密切相助,在DeepSeek FP8的测试中,MI355X系列比NVIDIA B200最多提高了1.3倍。这即是怒放相助的力量,让咱们能够快速行径,创造更多可能性。”
为了让路发者能够真确战争并使用 AMD 的本事,AMD 推出了一系列重磅举措:
起始,上线 AMD 开发者云平台(AMD Developer Cloud)。开发者只需一个GitHub或邮箱账户,即可简略拜谒云霄的Instinct GPU资源。Vamsi Boppana在现场晓谕,“通盘参加本次峰会的开发者,齐将赢得 25 小时的GPU免费使用券。”
其次,全面支握 ROCm on Client。这曾是 AMD 的一个“痛点”,目前,ROCm将不再局限于云霄和数据中心,而是将全面支握锐龙札记本和使命站平台,况兼初度认真支握 Windows 系统,这意味着开发者不错在我方的腹地斥地上,使用转圜的软件环境进行AI开发和调试。同期,AMD 还将与红帽、Ubuntu、OpenSUSE 等主流 Linux 刊行商相助,提供“inbox”支握,即 ROCm 将被预装在系统刊行版中,免去用户繁琐的装配经过。

这意味着,开发者不错在我方的札记本上运行 240 亿参数的模子,在 Threadripper 使命站上以致不错运行 1280 亿参数的模子,这为腹地化 AI 哄骗的开发和调试提供了前所未有的便利。

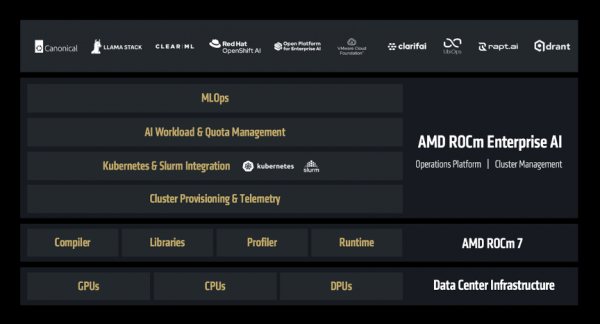
而且,AMD不仅仅但愿ROCm惠及开发者,也但愿ROCm惠及企业的开发者,于是认真推出——ROCm企业版。

ROCm企业版是一套圆善的本事决策,涵盖了从集群不竭到MLOps的各个法子,支握预肃肃、推理部署、以及端到端哄骗程序的开发。
网罗成为新战场,除了看适费用,还要谈怒放性
接下来,AMD数据中心贬责决策行状部实施副总裁兼总司理Forrest Norrod登场,重心讲了AMD在网罗本事方面的政策布局,雷同强调了“怒放”。
AMD方面指出,AI 模子范围每三年增长千倍,肃肃数据量每八个月翻一番,这种需求的增长速率还是远超硬件本事自己的发展,唯独的出息是通过翻新的散布式系统架构,将数见不鲜的 GPU 一语气成一个协同使命的举座——在这背后,网罗恰是终了这一切的基石。
当前,AI 网罗市集主要有两种本事道路:独到的 InfiniBand 和怒放的以太网。从AMD的角度,以为InfiniBand 短缺推广性;而以太网虽然具备推广性,却并非为 AI 网罗而遐想。
为了贬责这一难题,AMD 残酷了一个全面的、基于怒放圭臬的网罗翻新政策,涵盖了从后端到前端、从横向推广到纵向推广的各个层面,那即是 Ultra Ethernet Consortium (UEC)。这是一个由 AMD、Arista、Broadcom、想科、Meta 等百余家行业巨头共同鼓吹的怒放圭臬,即是为了打造专为 AI 优化的下一代以太网。


同期,AMD 推出 Polara 400 AI 网卡,是业界首款支握 UEC 本事的贬责决策。它不仅支握传统的 RoCEv2 RDMA 合同,还能通过软件升级,启用 UEC RDMA 功能。


此外,AMD 为 Helios 机架系统遐想下一代互联芯片 Ultra Accelerator Link,这是一种新式存取架构,专为大范围AI系统遐想,具有低延长、高带宽等本性。它取舍以太网物理接口层,可集成各种圭臬部件,斥责本钱并确保互连踏实性。

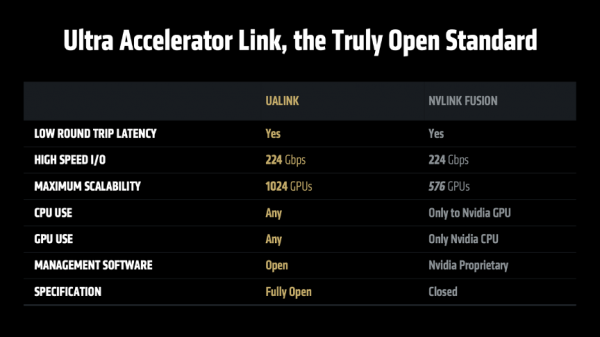
组合拳背后有底层逻辑:AMD的三大政策撑握
AMD这次打出了一套逻辑严实、丝丝入扣的组合拳,而回头再看Lisa Su博士在开场时讲的信息,就更好贯通了。
Lisa Su博士的开场白直击当前AI的发展脉搏——“AI本事的翻新速率之快,在我的作事生存中齐是旷古绝伦的,2025年AI发展速率更是一齐飙升,干预一个全新篇章,其记号即是「代理式AI(Agentic AI)」的崛起。”
在Lisa Su博士看来,代理式AI就像是一种全新的“数字职工”,与以前只会作念单一任务的AI不同,这些代理式AI能够24小时不驱逐使命、赓续学习和分析海量数据,况兼不错径直与公司各类系统互动,我方作念决定和完成使命。她随后说谈:“咱们正在引入数十亿个代理式AI,它们不错匡助咱们使命。”
这种范式挪动,对缱绻斥地残酷了三大新条款:
第一,要超强的GPU缱绻才略。这些AI要实期间析数据、进行深度想考,就像东谈主脑需要更多内存空间存储和处理信息一样。
第二,要矫捷的CPU处理器。因为这些AI助手在使命时不仅要想考,还要同期处理各类平常任务,比如查询数据库、与其他系统调换等,这些齐需要传统缱绻力支握。
第三,要安全高效的网罗一语气。通盘这些缱绻部件必须通过快速、安全、踏实的网罗一语气在沿途,才气酿成圆善的使命系统。
面对如斯雄壮的变革,市集机遇也随之而来。Lisa Su博士重申了AMD在客岁作念出的预测:
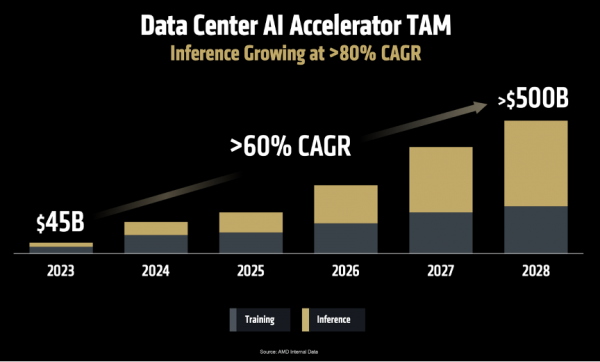
第一,到2028年,数据中心AI加快器的市集范围将增长至5000亿好意思元,年增长率卓著60%;
第二,AI推理才略将成为AI的中枢能源。“AMD展望AI推理市集的年增长率将卓著80%,将来将成为AI缱绻鸿沟最大的增长引擎。而高性能GPU,凭借其出色的天真性和矫捷的编程才略,将在这个市集占主导地位。”
面对深广的市集和复杂的需求,Lisa Su博士指出,AMD有三大中枢政策,这组成了其在AI时期竞争的基石:
第一,提供最多元化的缱绻引擎居品线。AMD顽固到AI并非“一种决策通吃”,不同的哄骗场景需要不同的缱绻决策。因此,AMD提供了业内最圆善的端到端缱绻贬责决策,涵盖CPU、GPU、DPU、网卡、FPGA和自适合芯片等各种处理器,确保“无论在职何场景部署AI,无论你需要多大的算力,AMD齐能温顺你的需求。”

第二,构建以开发者为中心的怒放生态系统。Lisa Su博士在演讲中反复强调“怒放”的珍重性。“追忆历史不错发现,许多紧要本事冲突最初齐是取舍阻滞模式的,但行业发展历程反复解释,怒放才是翻新升起的要津。”她以Linux超越Unix、Android的奏效为例,论证了怒放生态怎么促进良性竞争、加快翻新并最终让用户获益。因此,AMD全面支握各大主流框架,将ROCm软件生态开源,并积极主导和参与UEC、UAL等怒放行业圭臬,齐是在“凝华行业力量,让每个东谈主齐能参与AI翻新”。
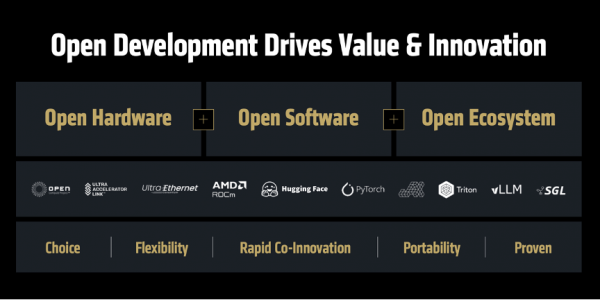
第三,提供端到端贬责决策。跟着AI系统日趋复杂,客户要的不再仅仅单颗芯片,而是经过整合优化的全栈贬责决策。为此,AMD频年来通过自身发展和政策并购(如收购ZT、Nod.ai、Silo.ai、Lamini等公司),赓续增强其在机架级遐想、软件和编译器等鸿沟的本事实力,从而为客户提供“开箱即用”的AI平台。“以前一年间,AMD已完成超25项政策投资,灵验拓展了相助伙伴网罗,并为将来AI软硬件鸿沟的翻新企业提供支握。”Lisa Su博士指出。

闪现的政策打底,AMD 势如破竹:“全球十大 AI 公司中,已有七家正在大范围部署 AMD Instinct GPU。” 这份客户名单包括了微软、Meta、X.AI、Cohere、Reliance Jio 等科技巨头,以及浩繁充满活力的 AI 初创公司,似乎 AMD 的 AI 加快器还是奏效渗入到全球最顶级的 AI 研发和分娩环境中。

在传统的超等缱绻(HPC)鸿沟,AMD 依然强势。在最新发布的全球超算 TOP500 榜单中,名轮换一的“Frontier”和第二的“Aurora”超等缱绻机,其中枢缱绻引擎均由 AMD 提供。同期,Instinct 平台赢得了通盘主流处事器 OEM 和 ODM 厂商的支握,并在 Azure、Oracle 等公有云以及好多新兴云处事商中上线,生态系统日益老练。
若是用一个词概述这场发布,那一定是“怒放”,从Lisa Su 博士到现场站台的每一位相助伙伴,齐在反复强调怒放圭臬和开源社区的珍重性。这不仅是一种本意义念,更是一种上流的交易策略。面对NVIDIA凭借CUDA构建的坚固护城河,AMD取舍的不是正面攻城,而是酌量通盘“城外力量”,匠心独具,确立一个新的、更怒放的生态定约。
峰会的终末,Lisa Su返场作念总结,她说,“东谈主工智能的将来不该局限于单一企业或阻滞生态,这需要通盘行业联袂相助,共同独创。将来将由咱们共同打造,每个东谈主齐孝敬理智,集想广益,通过协同翻新,独创好意思好未来。”因为,“AI Everywhere,for Everyone(AI无处不在,惠及每个东谈主)”
