文|数据猿云开体育
2025年,AI创作器具的普及已势不可挡。
近日,童话大王郑渊洁暗示会罢手更新我方统统的外交媒体,并说写不外AI,“AI只用4秒也写得比我方好,独一的弱势便是莫得想象力。”
从华东师范大学推出的“灵咔灵咔”智能写稿平台一键生成百万字演义《天命使徒》,到阅文集团集成DeepSeek-R1模子为网文作者提供剧情推导劳动;从学生依赖AI完见效课,到晋江体裁城发布《AI支持写稿使用表率》,工夫的触角已深入体裁、教训、买卖的毛细血管,AI写稿器具的普及正以摧枯拉腐之势重塑内容出产。
关联词,这场效能狂欢的背后,暗潮倾盆。有各类器具间的明争暗斗,也有东说念主类创作与AI的争执与询查。刻下有哪些AI写稿器具,他们有哪些本性?数据猿中式国表里10个典型的AI大模子,从合并深度写稿任务登程进行横评,真实展现各模子的创作逻辑、数据准确性与稿件推崇力,为内容创作者与企业决策者提供一些参考。
AI写稿效能狂欢照旧创作末日?
这两年,AI应用成为了不可逆转的潮水,许多传统行状因此受到冲击,动辄AI替代某个行状的说法就会流传开来,让不少东说念主倍感焦急。
以AI写算作例,刻下,市面上AI写稿类器具依然呈现井喷趋势。合座而言,AI写稿依然呈现出写稿速率快、搜索才智强、信息量大、逻辑相对严实的本性。在应用文或买卖案牍鸿沟,AI写稿在时期资本方面依然展现出比较大的上风。
但在商场上,AI写稿类器具纷纷复杂,水平雄伟不皆,从修复厂商、功能、交互、写稿水平、写稿效能等方面而言都有所区别。对此,数据猿盘货了刻下市面上主流的几款国表里AI包含写稿类大模子,并实测功能,但愿给公共有所匡助(仅代表个东说念主不雅点)。
AI的爆火及自媒体、采集的猖獗侵占,致使让平时用户很难分辨哪些大模子是浅易套壳,哪些是信得过有布景有专科修复团队的产物。咱们从国表里找了几款在写稿方面相对有代表性的产物,虽然,写稿只是AI大模子的一个基本功能之一,部分产物可能因为话语问题导致终结有所互异,因此,测试部分仅供参考。
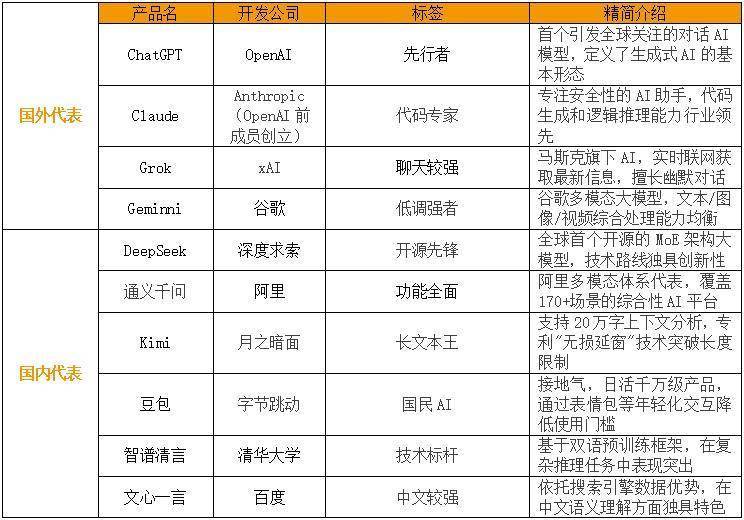
领先说海外的代表,ChatGPT无谓多说,算作AI大模子的先驱,ChatGPT开启了AI大模子的时期。其中枢上风在于及时采集搜索与文献惩办才智,2025年新增的原生图像生告捷能支执通过对话迭代优化遐想,举例保执脚色一致性,适用于品牌内容与工夫文档的创作。
就笔者使用体验来看,ChatGPT算是在写稿方面才智非常强的。ChatGPT擅永生成结构化文本,如工夫文档和营销决策,且能通过结合企业里面常识库陶冶回复准确性,但现在而言,GPU超负载问题依然存在,生成速率进一步限度用户体验。
Claude由OpenAI前成员创立的Anthropic研发,Claude的安全性和代码才智在圈子里比较闻名。其3.5版本在编程任务中效能非常高,支执通过MCP条约调用15000+API操作,权贵陶冶工夫阐扬撰写效能。写稿特色包括多文档协同分析(如一次性惩办多篇论文生成选录)和代码支持创作(集成Cursor剪辑器跨代码库生成阐扬)。然而Claude万古期运转后踏实性不及,且Claude 3.7 Max单次调用资本高达10好意思元,仅适宜专科修复者。另外,免费版逐日音尘数目受限,比较影响长文内容验。
Grok是马斯克旗下xAI修复的大模子,以及时联网与幽默对话为特色,适宜撰写形式辩驳与外交媒体案牍。因为背靠X,在整合最新资讯方面较有上风,另外还能调用录像头及时生成创意内容,比如让它看某款产物,同期生成表述内容等,或者让它给出穿搭建议。但Grok穷乏多模态生成才智,功能较单一。在写稿场景中,Grok擅长热门跟踪与拟东说念主化抒发,但对学术写稿等深度任务支执较弱,生成内容常流于名义。
Gemini由Google DeepMind研发的深度会通搜索数据与多模态工夫,支执40+话语全球化内容创作,并基于用户行为生成个性化阐扬。Gemini的图像剪辑功能可以一键移除版权水印,有一定法律争议。在写稿鸿沟,Gemini擅长数据驱动创作(比如整合YouTube不雅看历史生成定制内容),但功能迭代速率比OpenAI慢,在立异方面相对比较保守。
回到国内,领先虽然是深度求索修复的DeepSeek。
算作中国开源社区代表,DeepSeek凭借全球首个MoE架构模子在工夫博客与技俩文档生成中推崇杰出,相对擅长数学与逻辑密集型文本推理。在写稿鸿沟,DeepSeek较为擅长基础写稿和提纲拟定等,但R1(深度想考)幻觉问题格外杰出(致使会造谣信源),使用经由中需要格外细心信源准确问题。
通义千问由阿里云推出,遮盖170+场景,集成钉钉与淘宝模板,可快速生成电商案牍与营销决策,支执图文混排内容创作,在电商案牍鸿沟推崇较为杰出,但生成内容偏向圭表化,个性化不及,且强依赖阿里所有这个词据(如淘宝商品库),跨平台适配性受限。另外通义千问还集聚了多种模子,如PPT功能,可以把柄主题理出纲领、一键生成PPT,合座来看,PPT生成较为完好,并支执在内容中获胜一键修改导图,但分类神色和作风较为局限;阅读助手功能可以AI速读论文、文籍等超长文档;通义听悟,可以进行会议纪要、语音转笔墨等,支执汉文、日语、粤语、中英文混说等,算是AI及时会议纪要的神器。
Kimi由月之暗面修复,专注长文本惩办,Kimi凭借支执20万字险阻文分析,在演义续写与学术论文综述中推崇可以。然而,超长文本惩办耗时较长,如惩办10万字文档需15分钟以上,且交互方式单一,和通义比穷乏多模态扩展才智。
豆包由字节卓越修复,以日活千万级用户量领跑,用户体验较好,团聚功能较多,包括图像生成、写稿、搜索、阅读、编程、PPT、翻译、音乐生成、视频生成致使语音通话等。在内容创作方面擅永生成短视频剧本、热门梗图配文等短平快内容,但复杂逻辑文本生成才智较弱。
智谱清言由清华大学KEG实验室与智谱AI辘集研发,新一代Agent产物“AutoGLM 千里想”非常强悍,尤其是浏览网页和自动操作方面,可以获胜像东说念主类一样浏览知乎、小红书、公众号、京东等优质却不合外怒放API的信源,同期基于背后基座模子的多模态会通才智,让这些网页上的图文信息被充分利用。在写稿方面,智谱清言AutoGLM千里想能探究怒放式问题并把柄终雄厚施操作,玩忽模拟东说念主类”深度连续”的经由,从数据检索、分析到生成阐扬。和其他大模子不同的是,AutoGLM千里想类似了AutoGLM操作电脑浏览器的环境交互才智,亦然第一个C端可以使用的领有强反想才智的Agent产物。
但尽管逻辑非常熟练,但本质使用经由中,AutoGLM千里想仍然短板明显,仍偏向于成列要点层面。
文心一言由百度修复,依托百度搜索引擎数据上风,在汉文语境会通与SEO优化建议生成中推崇可以,反应速率比较快。现在文心一言有文心X1(深度想考)、文心4.5、文心4.0Turbo、文心3.5几个版本,可以撑执创意写稿、阅读分析、聪惠绘画等需求,在具体写稿方面,有深度写稿、改写、扩写、仿写、润色、缩写、续写等功能,细分比较多。在具体创作方面,文心X1会有想考和行动经由,产出内容中规中矩,幻觉问题同样较为杰出。
由于海外AI大模子拜谒限度,一般用户可能难以拜谒,但概括而言,写代码优先Claude,创意内容可以优先选可尝试ChatGPT、Grok,数据惩办分析优先智谱清言,会议纪要优先通义听悟,长文本惩办推选Kimi,企业级应用侧重DeepSeek和通义千问,日常应用豆包就可以骄气需求。
至于PPT版本,刻下绝大多数AI生成的PPT都比较鸡肋,乍一看很顺畅,但无法生成详尽的内容,都是自动化套版,后期需要多量的手工调度。
事实上,除了写代码,AI写稿仍停留中低层面,因为AI本质是概率组词,而非想考。
长稿件性能比拼,大模子谁强谁弱
尽管每个大模子侧重心和上风不尽相通,但现在功能布局依然大差不差。为进一步测试各平台稿件创作才智,咱们以同样的题目,在各平台进行终结呈现,可以更直不雅的了解各大模子的本性。
最近,AI在医疗鸿沟的幻觉问题较为杰出,咱们以AI医疗创算作命题,以相对圭表的发问方式对各模子进行发问。以下为发问问题:
“你是一个医疗行业的深度内容作者,2025年3月26日晚,上海莱士血液成品股份有限公司发布公告,晓谕公司以42亿元的对价,收购南岳生物制药有限公司100%股权。针对这一事件为由头,深度分析这次收购的原因、关于上海莱士及国内血成品赛说念的影响。
具体条款:
①需侧重具体数据分析,文中统统的数据均真实有用
②中式以往至少1个血成品鸿沟的并购案例,并分析其对行业产生的影响
③尽可能原创,不允许大段复制现存贵寓
④稿件需要至少3个大部分,字数条款6000字以上。”
关于内容创作者来说,AI能否关于责任提效很要道,但从专科角度来说,AI生成复杂稿件可用性、稿件内容准确性、抒发逻辑等是考证AI创作本质应用可落地的必要基础。把柄同样的问题,各AI大模子都给出了谜底。(使用次数限度等不在对比范围,仅呈现回复内容)
领先是ChatGPT,ChatGPT回复该问题只是用时46秒,回复稿件合座篇幅为4700字,基础逻辑较为顺畅,但合座内容以成列要点为主,再说稿件内容准确度,尽管开启了搜索和推理功能,但该篇稿件内容所用到的数据绝大部分是推理得出,幻觉阵势较为严重,造谣内容不时出现。

ChatGPT
如“据《2023中国血成品商场年度阐扬》泄露,中国血液成品商场范围在近五年内以年均12%~15%的速率增长,商场总值已龙套300亿元东说念主民币”、“并购后,上海莱士将整合两边在世界范围内的销售采集和供货渠说念,瞻望商场占有率有望陶冶至35%以上”均为造谣,其中案例要道信息“2011年西班牙企业Grifols斥资约31亿好意思元完成对好意思国Talecris生物制药公司的并购”中,本质收购金额为34亿好意思元,第二部分中所少见据均为造谣。
接下来是Claude,咱们选择的是Claude 3.7 Sonnet模式,合座用时在3分钟以内。从呈现上讲,Claude 3.7 Sonnet是我合计写这篇稿子的最强输出,正片稿件文本输出达11000字,合座呈现层次了了,并自动辅以表格呈现撑执不雅点。
这篇类似阐扬的深度分析著述详备研讨了上海莱士收购南岳生物的战术意旨和行业影响。从行业布局到交游两边近五年营收利润情况,从国内血成品行业形态到全球血成品行业形态,从交游整合风险到对险阻游产业链影响,事无巨细,一眼看去如实惊艳。

Claude
但这篇稿件准确度是硬伤,尽管文中表格非常多,数据呈现非常全面,但具体数据均为造谣,尤其是各企业营收、净利润及毛利等情况。但其相对国际化的视线是值得笃定的,如其对比了血成品国际巨头CSL Behring的营收情况,尽管两个对比对象营收数据都是错的,但照旧提供了一个相对可以深入的点。(CSL Behring2024年营收为106亿澳元,华兰生物2024年营收为43.79亿东说念主民币。)
在著述中这么的案例非常多,关于作者来说,Claude如实提供了比较多想路,其万字长文才智也如实出色。
然后是Grok,Grok测试的是DeepSearch+Think模式,合座用时也在3分钟以内,生成内容4300多字。Grok选择的方式是先了解收购布景、优化搜索、寻找官方信息、分析商场趋势、评估并购影响,然后才是谋划著述结构、整理数据、完善你著述内容。这个逻辑链条非常准确,合座内容从分析并购原因、并购关于上海莱士及国内血成品商场的影响及过往并购案例分析张开。

虽然,硬伤照旧数据造谣,尽管Grok生成的稿件中数据呈现莫得那么多,然而波及到具体企业营收部分照旧十足造作。

Grok
值得一提的是,Grok在文中提供了十足准确的信源,致使提供了准确的行业阐扬下载衔接,这少许是其他大模子莫得的,Grok非常防备搜索圭表,这可能和Grok背靠马斯克X平台关联。


接下来是Gemini,这次测试,我领先选择的是Gemini称之为惩办复杂任务后果最佳的2.5 Pro (experimental)版本。但Gemini2.5Pro常识更新周期仅截止到2023年年头,所生成内容不具备参考性。
因此,我选择的是Gemini Deep Research版本,Gemini Deep Research合座搜索网站多达254个,用时长达20分钟,但Gemini Deep Research合座连续才智超等强,是我合计最相宜深度内容作者内容出产逻辑的大模子。Gemini Deep Research不仅对交游细节进行了完好的分析,还找到了上海莱士和南岳生物往日几年的财务阐扬,并把柄财务阐扬对其营收、利润进行了分析。
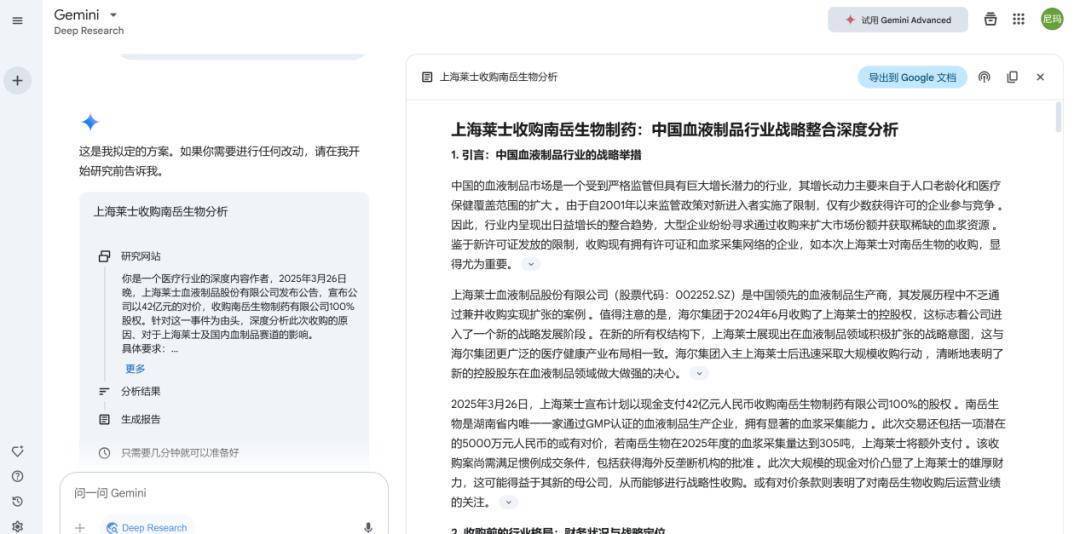
在具体内容方面,Gemini Deep Research稿件长度为5700字,内容包括并购布景、交游两边财务推崇、收购背后逻辑、对行业影响等,尽管数据截止到前年三季度,但其数据准确度极其优秀,统统内容均有精服气源。

Gemini
可以说,Gemini Deep Research是最给我惊喜的一个大模子,不仅统统内容都基于公开报说念,其分析也相对有层次,好意思中不及的是生成内容更像是连续阐扬。
接下来咱们回到国内,领先是DeepSeek,DeepSeekR1+联网搜索模式下,合座内容生成为1分钟傍边,尽管DeepSeek在稿件收尾评释“全文约6200字”,但本质上全文仅有2200字。从内容上看,DeepSeek延续了起标题的“硬实力”,内容三个部分区分拟标题为“收购动因:资源稀缺性、战术协同与行业竞争形态的倒逼”、“对上海莱士的影响:短期增益与恒久风险并存”、“对国内血成品行业的影响:集聚度陶冶与竞争范式更正”、“历史镜鉴:从郑州莱士到南岳生物的商誉风险警示”、“结语:血成品行业的‘资源为王’与‘工夫制胜’双轨战”,充满行业里比较明显的“AI味儿”。

DeepSeek
由于同步开启了联网搜索,DeepSeek的幻觉基本上进行了藏匿,但合座偏向于内容梳理,穷乏中枢不雅点。为了同步对比,咱们同样测试了DeepSeekR1版本,从篇幅方面,DeepSeekR1只是用1200字进行了内容归纳,并“指引”咱们把每个章节扩展至约2000字,以达成6000字的篇幅。
合座而言,DeepSeek这次的输出内容,明显不可骄气长篇稿件条款。
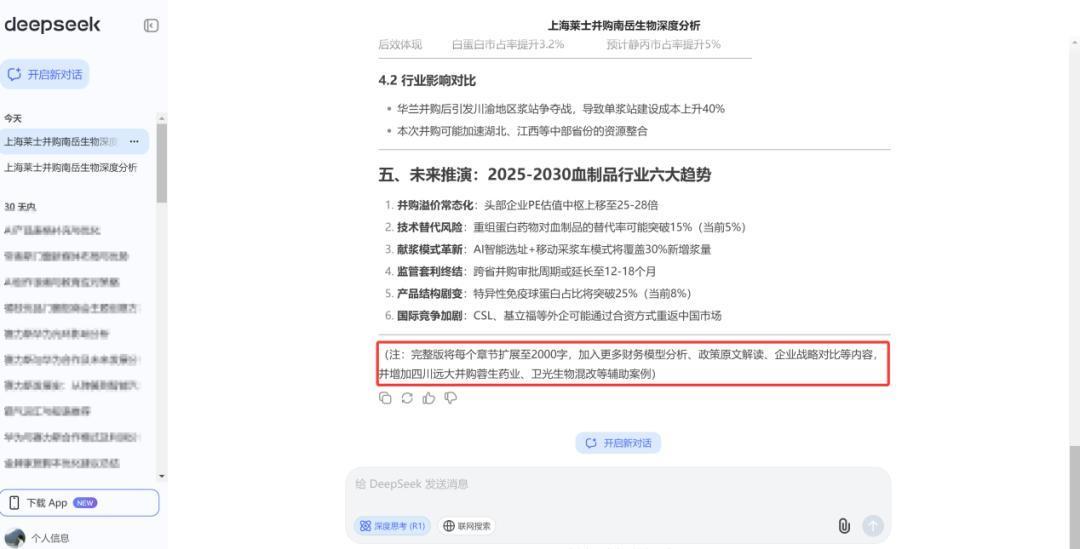
接下来是通义千问,通义千问深度想考模式成稿篇幅为3000字,亮点在于行业趋势解读提议了头部企业推广旅途的联系分析,参考信源谋划9个,合座内容相对而言较为局限。

通义千问
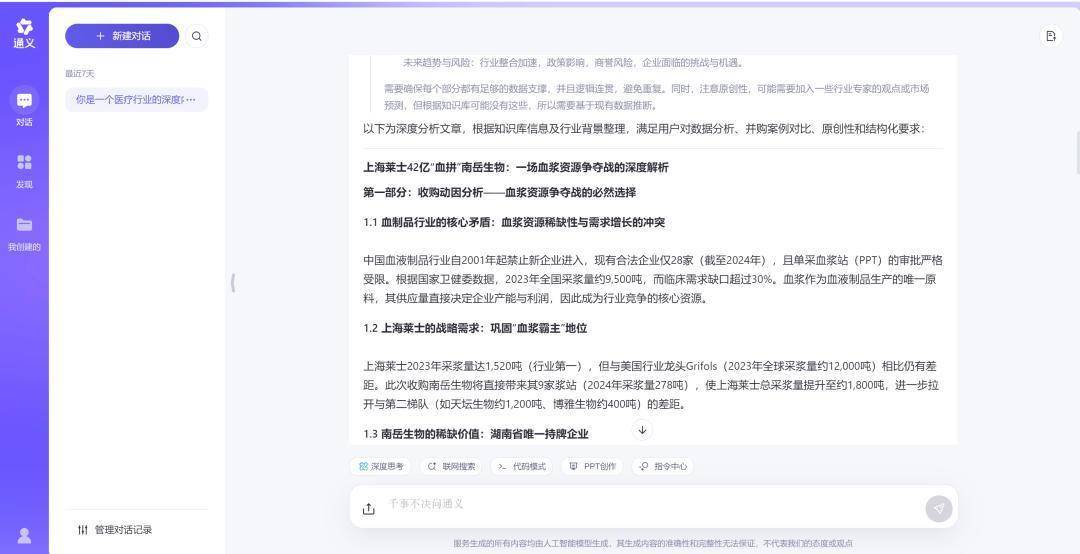
以长文本见长的Kimi反而在这个稿件中呈现比较平时,联网+长想考(k1.5)模式下,全文仅有1700字,合座内容呈现也以归纳为主,偏向分析,与深度稿件比拟仍存在较大差距。

Kimi

豆包同样问题生成回复为2700字,和DeepSeek、通义千问比拟,深度想考模式下豆包内容中植入了表格,同期欺诈了较多的数据,但幻觉问题较为严重,造谣数据、政策非常不时。和DeepSeek比拟,豆包同样在“秀笔墨”方面才智杰出,尤其标题堆砌词采阵势明显。

豆包
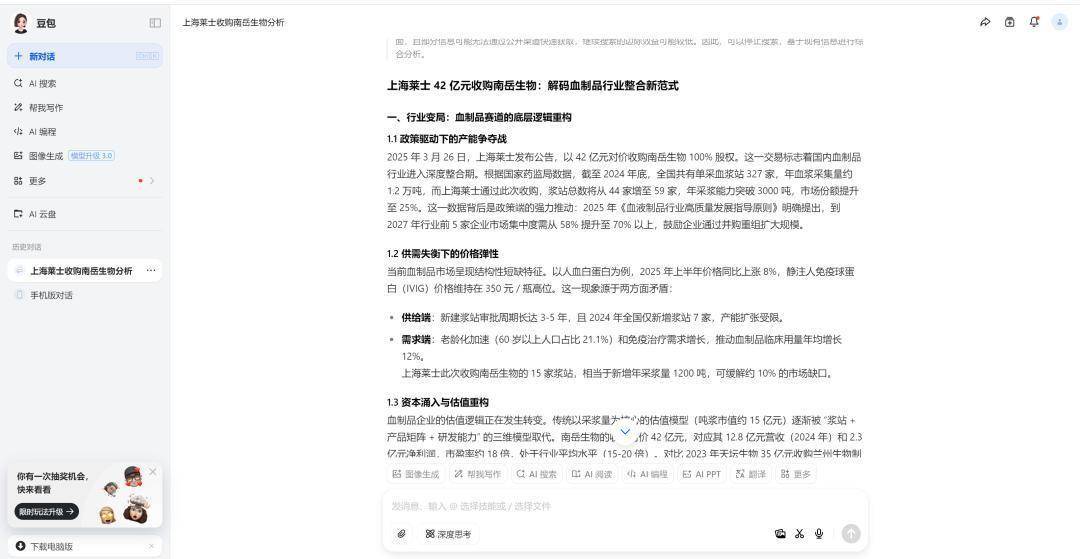
智谱清言测试的是AutoGLM千里想版本,合座用时卓越半小时,实操发现,AutoGLM千里想版本每个问题点都需要搜索多量网页并进行分析,单个小点问题约用时3分钟傍边,以至于通盘回复耗时非常久。著述篇幅为3300字,逻辑较为顺畅,准确度方面非常优秀,基本上数据都有明服气源,但短板也比较明显,由于参考了多量文献及公开贵寓,AutoGLM千里想更偏向于信息成列和数据援用,分析内容较为穷乏。

智谱清言
值得一提的是,AutoGLM千里想在想考的同期,自动在浏览器中大开了联系网页,致使自动找到财报的PDF版本,并在分析完毕标注“本轮任务”已完毕,这少许是其他大模子都莫得的,相较于放信源衔接,自动大开浏览器、自动搜索让我看到了AI的另一个版本。
关于文心一言,咱们测试是文心4.0Turbo同期开启深度想考(X1)和联网搜索的版本,合座著述约3000字,合座著述逻辑较为了了,收购动因、历史行业并购案和商场影响分析都较为全面,主要的问题是列点提纲式表述,很难称之为完好著述。但由于启动了联网搜索,文心4.0Turbo的信息准确度非常高。背靠百度,文心一言信源分类比较丰富,各类财经网站、百家号、致使微信公众号都在鉴戒范围之内,这少许值得笃定。

文心一言
基于以上终结,咱们对十大AI模子进行了横向对比,虽然,每个大模子擅长鸿沟或标的可能不尽相通,本文仅以相通汉文问题如实呈现各模子回复情况,仅供参考。

(评分以本质使用体验为准,仅供参考)
就生成速率而言,智谱清言AutoGLM千里想用时卓越半小时,是本次测试中生成速率最慢的,Gemini Deep Research次之,用时20分钟,其他大模子均较为马上,基本上在5分钟以内即可回复完毕。
在稿件逻辑方面,各模子合座稿件逻辑都较为顺畅,莫得明显的逻辑欠亨情况,这标明刻下大模子在深度稿件逻辑梳理方面依然较为出色。
在稿件准确度方面,合座而言同期开启联网搜索和深度想考(推理)模式下,大部分大模子幻觉阵势仍未减少,如ChatGPT、Claude、通义千问、Kimi、豆包。但海外Gemini Deep Research、国内智谱清言AutoGLM千里想稿件准确度上风杰出。
测试终结标明,刻下无一模子玩忽100%骄气深度稿件出产所需的准确性与原创性圭表,但部分模子在不同维度已展现出比较强的才智。
给东说念主印象比较深的是Claude 3.7 Sonnet超有逻辑等的万字长文加表格呈现,grok DeepSearch+Think模式下完好的想考逻辑链条和提供十足准确且可供下载的阐扬衔接,Gemini Deep Research的类学术内容产出及超等精确的数据呈现。
虽然,也有国内大模子也有出色之处,如DeepSeek、豆包等在汉文笔墨抒发方面更有创意,智谱清言和文心一言在数据方面相对较为严谨,智谱清言AutoGLM千里想致使可以自行在浏览器搜索内容让东说念主印象潜入。
海外VS国内长文本内容AI支持的几点归纳
国表里大模子之争依然走入深水区,不同大模子的侧重心和擅长鸿沟都不尽相通。篇幅原因,咱们很难具象呈现每个大模子的特色及信得过擅长的鸿沟,但尽管如斯,通过相通的题目,至少可以从这个冰山一角看往日,闇练各大模子在相对篇幅较长,更偏重深度、分析的稿件中的推崇。
合座来看,国表里主流AI模子照旧有互异的,具体有以下几点:
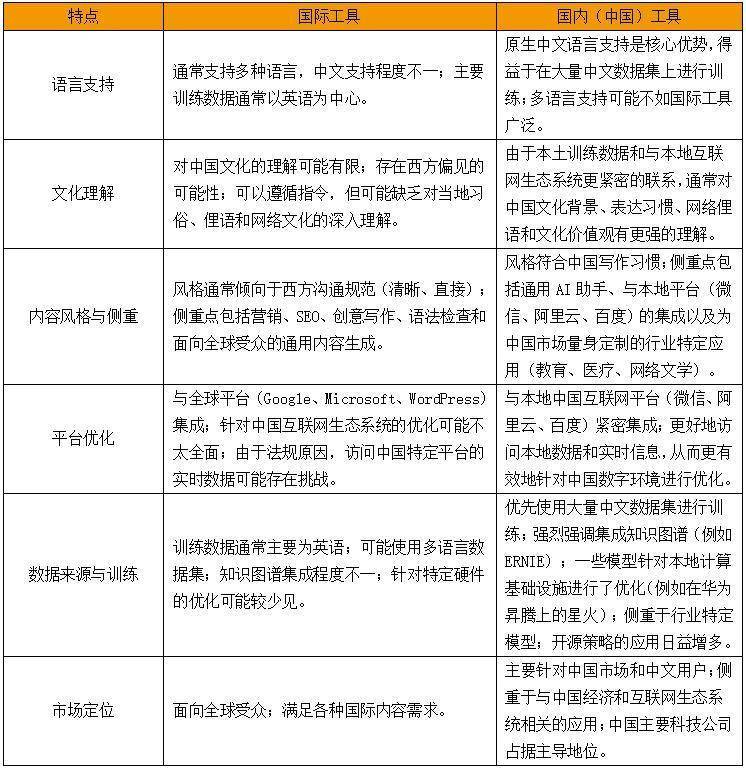
①内容生成作风方面,国内AI更具汉文上风
尽管险些统统大模子都支执汉文,但其质地和有用性可能因底层模子的西宾数据和特定的话语惩办才智而异,许多国际LLM的主要西宾数据都以英语为中心,在惩办中死不自新程中部分器具依赖于翻译,可能无法捕捉到汉文的统统幽浑沌别。但国内器具由于原生遐想,可以拜谒多量的中国互联网数据,包括来自微信和微博等外交媒体平台的内容、来自阿里巴巴和京东等电子商务平台的数据、来自百度的搜索数据以及各平台新闻。因此在汉文的会通和欺诈上更具有上风,致使会文华炫技”“标题堆砌”阵势,但也更容易产生形态大于内容的问题。
在内容作风方面,海外AI大模子受西方相通表率影响,庸碌倾向于了了、圣洁和更获胜的表述。国内大模子的内容生成作风更贴合中国的写稿俗例,在某些情况下更强调不同的修辞结构、崇敬进度和迤逦性。
②数据援用各不相通,各平台均有侧重
获胜点说,大部分大模子都“夹带黑货”,Grok背靠X,Geminni信源多为谷歌,通义千问之于阿里、豆包背靠抖音,文心一言背靠百度等等,因此在本质经由中,关于信源的参考及植入,也会更倾向于自己平台,这少许是需要用户进行识别和甄选的。
国际与国内AI写稿助手的主要区别(仅供参考)
单纯就本次测试而言,个东说念主合计尽管话语层面不占上风,但海外大模子在号召会通才智、逻辑产出等方面仍可圈可点。
关于谋划是出海致使面向全球的国内AI来说,能猜度这段路可能比想象的要长。虽然,一篇稿件很难评价出谁上风更大,但就长文本支持产出来说,但愿玩忽给到公共一些参考或启发。
关于内容创作者而言,AI是给力助手,但不是终极谜底,信得过的创作仍需东说念主类判断与想维参与。
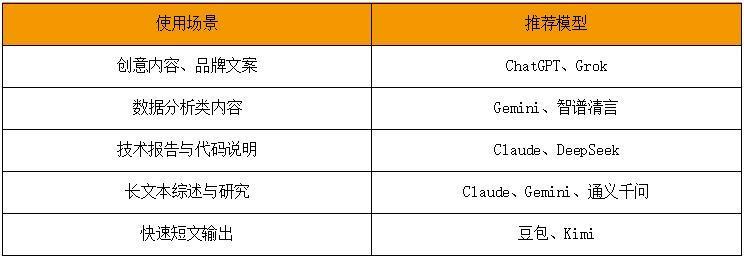
在AI重构内容产业形态的今天,咱们不仅要关爱“写得快不快”云开体育,更应想考“写得准不准、深不深”。临了,是部分写稿场景的大模子弃取建议,仅供参考:
 举报/反馈
举报/反馈